Google s Gemma 4 AI models get 3x speed boost by predicting future tokens

The story
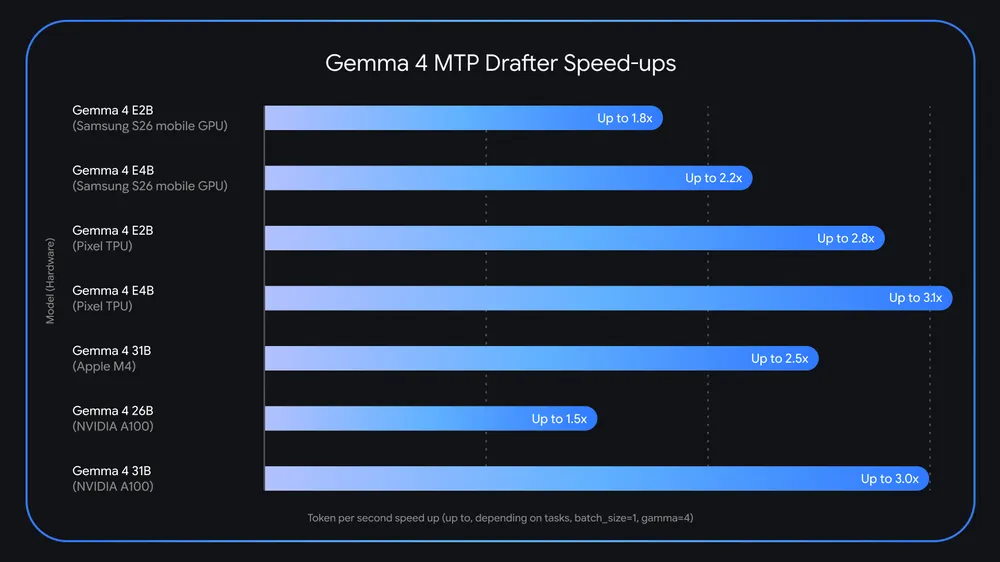
Up to 3x the speed with no loss of quality—is it too good to be true?
From the source
Text settings Story text Size Small Standard Large Width Standard Wide Links Standard Orange Subscribers only Learn more Minimize to nav Google launched its Gemma 4 open models this spring, promising a new level of power and performance for local AI. Google’s take on edge AI could be getting even faster already with the release of Multi-Token Prediction (MTP) drafters for Gemma. Google says these experimental models leverage a form of speculative decoding to take a guess at future tokens, which can speed up generation compared to the way models generate tokens on their own.
The latest Gemma models are built on the same underlying technology that powers Google’s frontier Gemini AI, but they’re tuned to run locally. Gemini is optimized to run on Google’s custom TPU chips , which operate in enormous clusters with super-fast interconnects and memory. A single high-power AI accelerator can run the largest Gemma 4 model at full precision, and quantizing will let it run on a consumer GPU.
Gemma allows users to tinker with AI on their hardware rather than sharing all their data with a cloud AI system from Google or someone else. Google also changed the license for Gemma 4 to Apache 2.0, which is much more permissive than the custom Gemma license Google employed for previous releases. However, there are inherent limitations in the hardware most people have to run local AI models. That’s where MTP comes in.
Who and what
Key names and topics in this story: Google, Gemma.
Where to follow next
- Read the full piece at arstechnica.com
- More from our AI & prompts coverage

Related stories
Google s Gemma 4 open AI models use "speculative decoding" to get up to 3x faster
Up to 3x the speed with no loss of quality—is it too good to be true?
Google updates AI search to include quotes from Reddit and other sources
While citing web forums and discussion boards can help users find answers to more niche queries, this design choice could also prove chaotic.
Google updates AI search to include expert advice from Reddit and other web forums
While citing web forums and discussion boards can help users find answers to more niche queries, this design choice could also prove chaotic.

Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4: Delivering Up to 3x Faster Inference Without Quality Loss
Google Introduces MTP Drafters for Gemma 4 Family Using Speculative Decoding to Achieve Up to 3x Speedup The post Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4: Delivering Up to 3x Faster Inference Without Quality Loss appeared first on MarkTechPost .